In the race to build ever-larger AI systems, one invisible cost has quietly been eating away billions of dollars: tokens.
Every piece of text that an AI model reads, from a short invoice to a 200-page contract, is converted into thousands or even millions of tokens. These tokens are what large language models (LLMs) process, and they directly determine how expensive and scalable an AI system can be.
Enter DeepSeek-OCR, a groundbreaking approach that reimagines how AI interprets and encodes visual text data. By combining vision models like SAM and CLIP with a Mixture-of-Experts (MoE) decoder, DeepSeek-OCR dramatically reduces token usage, quietly solving one of the biggest cost and scalability challenges in AI.
More details: https://github.com/deepseek-ai/DeepSeek-OCR
The Hidden Cost of Text Tokens
At first glance, text seems lightweight. But when processed by an LLM, even simple PDFs can become computationally massive.
For instance, a single invoice can generate between 1,000 and 5,000 tokens, while a full legal contract or report can reach hundreds of thousands of tokens.
At scale, this token explosion becomes a financial nightmare, inflating both inference time and infrastructure cost. In enterprise applications where millions of documents are processed daily, token inefficiency directly translates into billions of dollars in operational expenses.
Why OCR Wasn’t Enough
Traditional OCR (Optical Character Recognition) systems convert images of text into machine-readable strings. While effective for extracting characters, they fail to preserve the spatial layout, visual cues, and semantic grouping that humans intuitively understand.
This loss of structure and context means that LLMs must relearn layout and meaning, requiring even more tokens. In essence, OCR solved character recognition but not context recognition.
The DeepSeek-OCR Approach
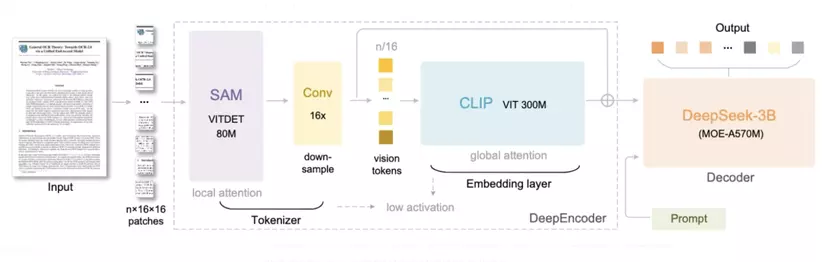
DeepSeek-OCR changes the game by combining computer vision, natural language processing, and model efficiency into a unified system.
Its core innovations include the Segment Anything Model (SAM) to identify and isolate key regions in an image such as tables, paragraphs, and diagrams; CLIP (Contrastive Language-Image Pretraining) to align visual content with textual meaning; and a Sparse Mixture-of-Experts (MoE) Decoder to intelligently select specialized sub-models for each segment, reducing redundant computation.
This architecture allows DeepSeek-OCR to compress long documents into fewer, denser representations, reducing token counts while preserving semantic fidelity.
Context Compression: The Real Breakthrough
At the heart of DeepSeek-OCR lies context optical compression, a method of encoding visual and textual information in a way that’s optimized for LLMs.
Rather than converting every visible word into a token, the model extracts high-value context embeddings that summarize content at a much higher level of abstraction.
The result is up to 10 times fewer tokens per document, faster inference across downstream AI models, and significant cost savings in training and inference pipelines.
This means AI systems can now handle longer documents, maintain context over hundreds of pages, and still remain cost-efficient.
Why This Matters
DeepSeek-OCR’s innovations go far beyond document processing. They address a foundational challenge in AI scaling: the trade-off between context length and cost.
By reducing token load without losing meaning, DeepSeek-OCR enables scalable multimodal AI that can process entire archives or knowledge bases, enterprise-level document intelligence in legal, financial, and medical domains, and faster, cheaper LLM integration in production systems.
As AI systems continue to expand, efficient tokenization becomes not just an optimization but a necessity.
The Billion-Dollar Impact
The implications are enormous. If global enterprises could cut even 30 percent of their AI inference costs, the savings could reach billions of dollars annually.
More importantly, it unlocks new use cases such as real-time document understanding and knowledge graph generation that were previously too expensive to deploy at scale.
DeepSeek-OCR has quietly turned what used to be an economic bottleneck into an engineering breakthrough.
Challenges Ahead
While promising, DeepSeek-OCR still faces several challenges such as handling extremely diverse layouts and handwriting, ensuring consistent accuracy across low-quality scans, balancing compression with information retention for long documents, and adapting the technology for edge or low-resource environments.
But its trajectory is clear, a move toward more efficient, multimodal, and cost-aware AI infrastructure.
Conclusion
DeepSeek-OCR represents more than an upgrade in OCR technology. It is a strategic leap forward in how AI processes and scales textual information.
By uniting vision models, context compression, and intelligent decoding, DeepSeek-OCR has quietly solved one of AI’s most expensive inefficiencies: the token bottleneck.
As the next generation of AI applications demands larger context windows and richer multimodal reasoning, technologies like DeepSeek-OCR will form the backbone of scalable, affordable, and contextually intelligent AI.
In short, DeepSeek-OCR didn’t just make OCR smarter, it made AI scalable.