In the world of artificial intelligence, large language models (LLMs) are getting smarter and more capable — yet they still face one critical limitation: handling long contexts.
When dealing with multi-page documents or research papers, feeding millions of text tokens into a model quickly becomes expensive in both computation and memory.
That’s where DeepSeek-OCR comes in — a groundbreaking approach that compresses textual, structural, and visual information from long documents using images instead of raw text.
What Is DeepSeek-OCR?
Released on October 21, 2025, DeepSeek-OCR introduces the concept of Context Optical Compression — a method that encodes entire documents as images, then uses a vision encoder to generate compact vision tokens.
These vision tokens capture not just text, but also layout, tables, charts, and formulas, preserving the full visual context of a document.
💡 Example: A typical PDF page might require 2,000 text tokens,
but DeepSeek-OCR can represent it with only about 200 vision tokens — roughly 10× compression without significant information loss!
Core Architecture
DeepSeek-OCR follows a two-stage design: Encoder → Decoder.
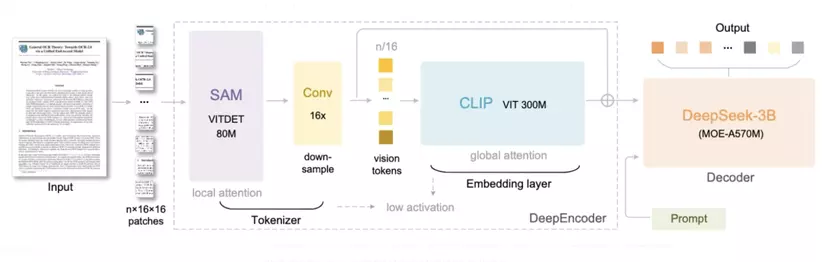
Encoder (DeepEncoder)
Input: rendered document images (e.g., 1024×1024 pixels).
Mechanism: combines windowed self-attention for local regions and global attention for overall page layout.
Down-sampling module: reduces the number of patches drastically (e.g., from thousands down to a few hundred).
Output: a small set of vision tokens that efficiently represent the document’s content and structure.
Decoder (DeepSeek-3B-MoE)
Based on a Mixture-of-Experts (MoE) model, where only a few “experts” are activated per inference step — improving efficiency without losing flexibility.
Output: plain text or markdown, preserving layout, equations, tables, and multilingual content.
Performance and Benchmarks
DeepSeek-OCR shows impressive performance across multiple datasets:
With a compression ratio <10×, it achieves 97% OCR accuracy.
At 20× compression, accuracy drops to about 60%, indicating an optimal compression threshold.
A single NVIDIA A100-40G GPU can process over 200,000 pages per day in production settings.
On OmniDocBench, using just ~100 vision tokens per page, DeepSeek-OCR outperforms previous OCR systems with far more tokens.
Limitations and Challenges
Despite its innovation, DeepSeek-OCR still faces several challenges:
Compression trade-off: excessive compression leads to missing fine details like small fonts or thin lines.
Image resolution dependency: complex layouts, formulas, and tables require higher input resolutions.
Hardware requirements: optimal performance needs GPUs supporting Flash-Attention, CUDA ≥ 11.8, and synchronized libraries (PyTorch, flash-attn, etc.).
The project is still in an early research phase, not yet fully optimized for production-scale deployment.
Applications and Impact
DeepSeek-OCR is more than just another OCR system — it’s a foundation for next-generation multimodal LLMs.
By compressing long contexts through vision encoding, it enables:
LLMs to handle much longer documents at a fraction of the cost.
Preserved document layout — including tables, images, and charts.
Direct question-answering over PDFs, research papers, or slides.
Seamless integration into enterprise and academic data extraction workflows.
Future Directions
Several exciting research paths are emerging:
Improving MoE routing efficiency for better expert utilization.
Finding the optimal compression ratio balancing cost and accuracy.
Extending the approach to videos, multi-page documents, or long-term memory systems for LLMs.
Combining DeepSeek-OCR with text summarization pipelines for an end-to-end “compress-and-understand” system.
Conclusion
DeepSeek-OCR marks a breakthrough in context compression via visual encoding, allowing LLMs to “read” and understand long documents more efficiently than ever.
Though still in its early stages, this technology paves the way toward an era where AI can comprehend entire reports, research papers, or even textbooks directly from images — fast, efficient, and remarkably scalable.
DeepSeek-OCR isn’t just about text recognition — it’s the bridge between vision and language for the next generation of AI.